Hi kazar!
this is a very good topic indeed, thanks for bringing it! I’m sure that there are lots of different opinions on this and that it is debatable and always good to know the best practices of others!
You touch here a design problem that IMHO is not as clear cut as you show it here and for which there is always decisions to make depending on what you want to achieve. I can actually see a few drawbacks to your approach, even though it works very well in some case.
The biggest problem here, I think, is database constraints. In your design, how do you ensure referential integrity in your database?
If every value list is in one table and you actually use fk constraints in the database, you will have them coming from a lot of different places in your graph, and each of them will have to have the relevant type in a compound foreign key.
Consider this design for example (inspired by yours):
[attachment=1]example_design.gif[/attachment]
(BTW this was done in Servoy with Aquarius ORM Studio  )
)
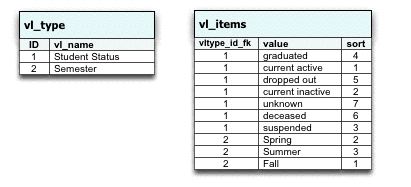
No you can see that I have constraints from student to student_status, and that I have constraints from semesters_courses (a many-to-many table) to semester. Now If I put everything into one single table, these 2 tables will point on it, with the additional overhead of having to deal with a compound key (2 fields to define the one relation).
I’m not saying that your idea is not valid, it can well be depending on the way you code it - from what I undestand of your value lists, they are used only for “selecting” values, and the “selected” value is then copied into the “calling” table, is that it?
It has some advantages but it also have disadvantages when users change the values of the value list table, because then the copied value is standalone and will not be updated as well.
In some cases, this is exactly what you want, of course: imagine tax values, you wouldn’t want all the tax values of the already billed invoices to change when a tax changes, do you? But then in some other cases you will want the values to be updated, meaning that the real values will only live in the vl table and you only store an id in the calling table (like in the design above).
As for the advantage of adding record in the vl_type and corresponding values in the vl_items table to have a new type with no coding at all, I doubt that you will not have to adapt your code to be able to use your new type anyway. In any case you will have to change the other tables to use this new “kind” of vl, and to change the code accordingly. So the “no code” advantage is not that obvious to me.
And then there is the performance factor. I’m not sure that having everything inside one table is such a good idea, it might become a little bit crowded with time, you can always use indexes but they too have their own pitfalls. And every time you will hit this table in SQL you will have to add the filter to retrieve the relevant type…
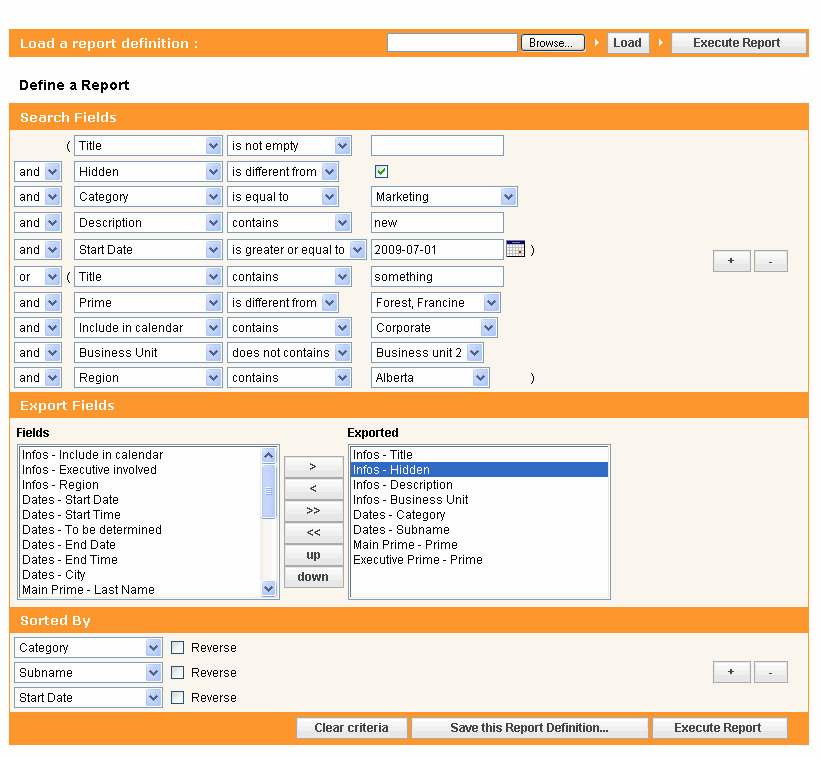
I have had to build (in java for the web) a search engine capable of dealing in SQL with any kind of runtime searches (meaning the user can add any kind of criteria, with any kind of operators and combine them at runtime) and I can tell you that dealing with different “lookup” tables is actually easier than having to deal with one filtered by a type.
Consider the interface below, and understand that behind each line of query that deal with a value list (these are the combo-box here), you would have to add two criteria instead of one if the value lists were all into one table:
[attachment=0]searchEngine.gif[/attachment]
So I would say that your approach works great depending on your code and what you want to achieve, but it is not always the best answer.
I’m sure that others will have again diverging opinions on that matter, and I would love to see the definitive answer to that kind of design problem, but I fear that it will always be a design time decision that you will have to do every time you design a system.
But I’d love to hear the opinions of those with a long experience of Servoy in production and see what has worked best for them from the Servoy perspective…