I was wanting the user to be able to add a few columns to a table - at runtime.
I can easily write the SQL to do the ALTER TABLE - but then Servoy doesn’t seem to “know” that the column is there… is there away to tell Servoy to “refresh” it’s internal column listing so it’s aware of the new column?
I have to be honest: I am also very interesting in a solution to this.
This is why:
My research analysts need to run regressions over data stored in a relational database. They don’t know how to parse data and turn relational tables onto one single table with dummy variables. Hence, I would like to write a method that will allow the analysts to select (or unselect) which data point they want as dummy variable, and so the method will be triggered, creating a column with the dummy variable (Boolean 1 or zero) of the data field they need to analyze.
mboegem:
If I’m not mistaken Tano will allow you to add columns via the solution model.
What about removing a column? Will Tano allow you to remove columns via the solution model?
Although not an answer to your question, perhaps a solution to the problem:
We solve this with a separate properties table per table-you-want-your-users-to-add-fields-to.
This properties table looks like:
+--------+--------------+--------------+------------------+
| Id | ObjectId |PropertyId | Propertyvalue |
+--------+--------------+--------------+------------------+
where Id is the Id of the properties table, ObjectId is a foreign key to the table-you-want-your-users-to-add-fields-to. PropertyId is a foreign key to a table listing the names of all user-defined properties and the Propertyvalue is, well, you know.
There are a couple of benefits to this approach:
The solution doesn’t have to keep track of changes in the datamodel.
The database won’t grow beyond control due to users adding a 100 fields just for the fun of it.
By indexing the properties table alone there is no need to index those user-defined properties.
Easy access to all property values with a relation or by joining the table-you-want-your-users-to-add-fields-to with the properties table.
Improved database performance if you need to do intensive analyses on those user-defined properties due to the fact that the user-data is stored more efficiently in database pages.
but as always there are drawbacks as well:
You need to think about the datatype of the user-defined stuff beforehand. You might need to create multiple value fields to store bothe integers, strings etc…
SQL queries on the data will involve joins, that might make it less accessable to users with only limited SQL skills
If I’m not mistaken Tano will allow you to add columns via the solution model.
This is not correct or at least it’s not the full story.
In Tano there’s a Maintenance plugin that allows you to perform datamodel changes through scripting. This plugin is only available in Maintenance mode: a mode of the Application Server that disabled the ability to start new clients. Entering Maintenance mode can be done manually on the admin pages or through scripting in the before and after solution import hooks.
So, it’s not the solution for creating columns on the fly (nor deleting them).
Jeroens suggestion is a good option, but take into his pro’s and con’s.
Another option you have is using temp tables (tables of which the name is prefixed with ‘temp_’). You can create tables prefixed with “temp_” yourself while the Servoy App Server is running and when Servoy encounters an object based on a temp table and the temp table definition is not yet known to Servoy, Servoy with read the table definition from the database and add it to Servoys info on the database model. Afterwards, you can use the table just like any other. Note that once Servoy has loaded the tables info, any alteration to the table will not be know to Servoy, unless you restart the Server.
Thanks for the options. I’m a little confused, though
Jeroen - your idea is to just have a table pre-defined with 100 fields - some text, some integer, some date, etc - and then store the meta data about what each user calls it, etc?
Paul, I get the fact that Servoy will allow you to add a table starting with “temp_” - and it will read in the definition and you’re good to go. That’s OK on startup - but what if the user wants to add a column (removing isn’t a problem, I can just “hide” them from the user and remove from valuelists, etc)?
They are going to be able to import data into these tables, export data from them, etc.
I’m building a SaaS solution for the iPhone builder - and people are not starting with their own table. They need to be able to build one “on-the-fly” and then be able to add columns (and ideally remove them).
Are there any ideas on how to achieve this - that will work?
this solution does not invlove a table with a 100 fields, just a table with 4 fields (5 in a SaaS model) as I sketched and a table with 2 fields. The first table holds the data, the second table holds the ‘datadefinition’ if you like. You could skip that second table and just use a character field to store the fieldname right within the datatable but proper normalization dictates to split those tables, something you will appreciate if someone wants to change the propertyname which will affect a couple of million records. In our case that datadefinition table only holds a name for the user-defined field.
If the users adds muliple fields to a table and would store values in those fields, he would end up with multiple child records in the data table for each mother record.
If you need to store data with varying datatypes, you would have to extend that 4-field table with multiple value fields, one for each field you want to support (using some sensible max. fieldlength)
In our case, we use separate tables to store user-defined fields for every basetable where we want to support this, so we end up with for example an Article table (holding the default fields available to all tenants in the SaaS model), an ArticleAttributeValues table holding the data and an ArticleAttributeName table holding the names of the fields. In fact, we have a fourth table called ArticleAttributeChoices which list the individual values for a valuelist because we offer the end-user the ability to associate a user-defined valuelist to his own field-types.
We do the same for Customers, Suppliers etc… Of course, you could store everything in just one set of property tables but then you would need some additional field to keep the properties of different tables apart. We prefer to split them to keep the tablesize more managable for each of those datatables can easily grow to a couple of billion records.
THANK YOU for the clarity! I’m very dense sometimes…
So, if your user adds 30 of their own fields to a table - you’ll have 30 ROWS of child data per single ROW of “master” data. I get it now. It’s like with the PDF form stuff - every field for every form is a single row.
So then if you wanted to support each of the datatypes - your “values” table would have one varchar, one int, one float, one blob, and one datetime column - right (of course you would need to also have the fk for the user, tenant, etc in addition).
How does this work in the “real world?” Any problems so far? That table could get pretty big, pretty fast! You then link to your main form - and have some way for the user to see that data (a tableview or per-session form with the SolutionModel)?
yes you got it, that’s how it works.
We’ve been doing this for ages in Foxpro, non SaaS, one DB per client. We are incoprorating it in our new Servoy SaaS model of the same app.
So far, we have test installations with 500+ tenants where the tables involved grew to about 300 million records without problems. Of course, the backend DB server is not of the “my first Sony” flavor.
We use the data in various ways. Some of these property names are configurable in the app. so we can dynamically build relations to that datatable to display the data, show it in tableviews as you mentioned and using the metadata to table-drive report generation. So the user can pretty much use all of his user-defined stuff in report sorting, filtering and grouping right out of the box, no consultants needed.
THANK YOU again! I’ll have to consider it. It will mean a major re-engineering of the solution I’m working on - but it sounds like it’s the only (Servoy) solution there is.
I really appreciate your ideas and for sharing your real world experience! I hope to see you at Servoy Camp in a few weeks…
Thank you for the very clear explanation of what you are doing. We have been doing something similar with our Contacts file, allowing users to create an unlimited number of phone numbers, email addresses, URLs, etc. for each Contact and it has worked very well. I can also confirm based on our experience hosting our PDF solution over the past three years that your approach works well with many millions of records.
Your PropertyId column is particularly interesting. I think your approach will become more and more popular in future Servoy solutions (think Salesforce.com).
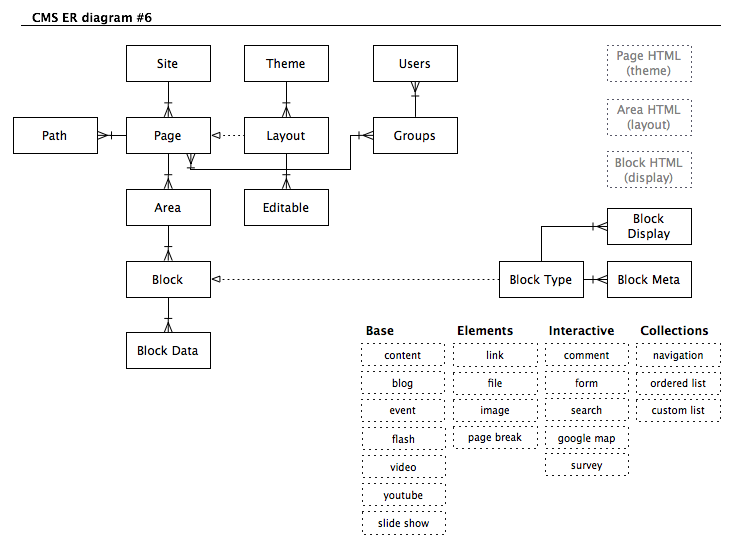
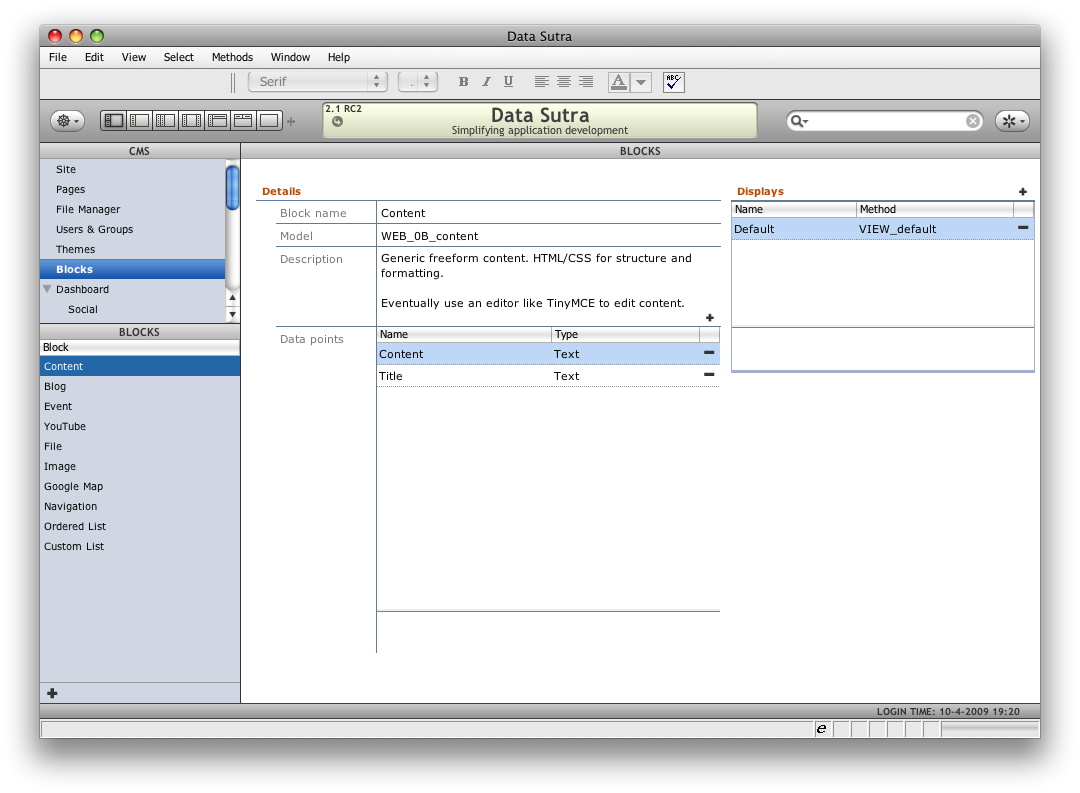
I’ll throw in another example usage: in a content management system to define the model for various types of content (block_type and block_meta in the attached ER diagram).
The twist in this instance is not because we needed to define columns on the fly. We wanted a consistent user interface for defining content types and for data entry – and then a simple standard way to code various markup based on the data map and the data. So instead of having to create new forms, adding them via tab panels to the definition and data entry forms – each new content type can be brought online by just setting up the required data points, and then writing the method (or methods) for the markup creation.
Two main advantages:
1- The form the user uses to enter the data for a web page stays the same no matter what kind of content they are entering.
2- Defining various content types – no matter what their data structure and display code is – is done the same way.
So this method is useful not only for the fact that is about the only way to accomplish flexible storage structures on the fly, but to also simplify your code base.
Example code that combines markup with data:
function VIEW_default()
{
// input
var data = arguments[0] // map
var params = arguments[1] // filter
// 1) get data from map and filter if data not in map already
// 2) build results
var markup = '<div id="data-<<id_block_data>>">\n' +
'\t<b><<title>></b>
\n' +
'\t<<content>>\n' +
'</div>'
markup = markup.replace(/<<id_block_data>>/ig, data.id_block_data)
markup = markup.replace(/<<content>>/ig, data.Content)
markup = markup.replace(/<<title>>/ig, data.Title)
// return
return markup
}
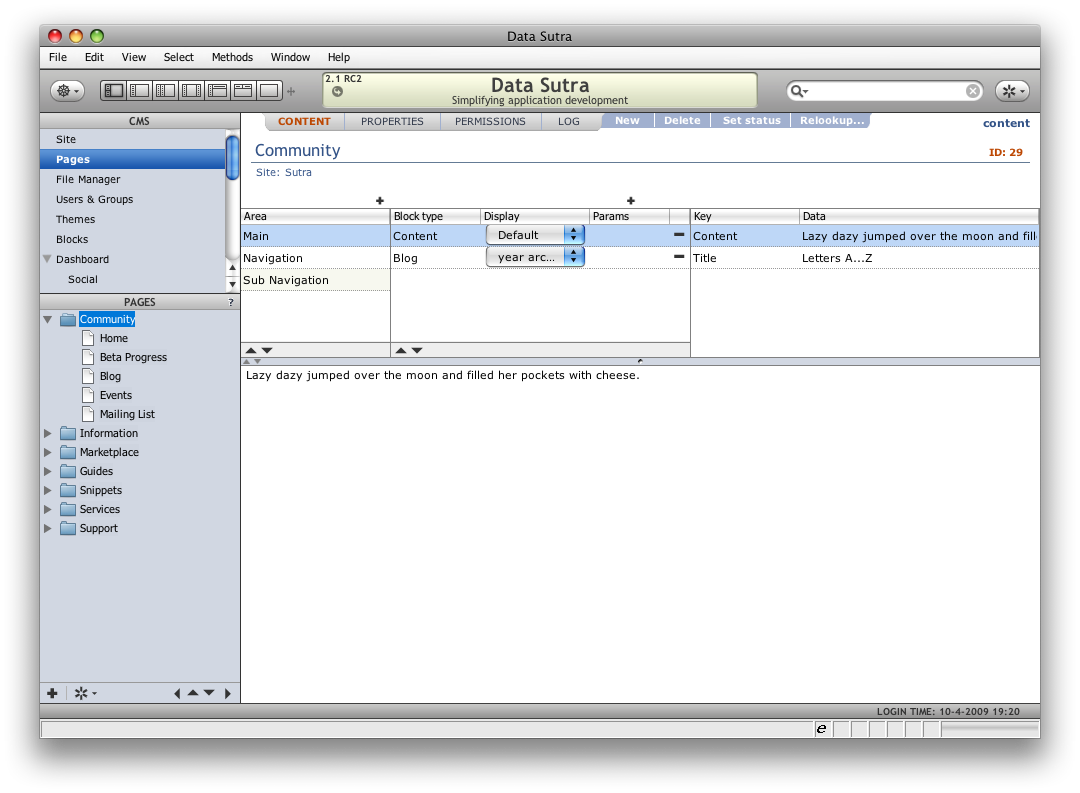
There is one method that builds a page of data on a browser request. It loops through all the areas and content blocks building the final markup for each block of data it encounters based on the markup method assigned for that block type:
Makes a fairly complex process simple to understand and communicate to other programmers who want to extend the CMS with a new content type. Just define your data points and create at least one markup method – all the other screens and main page code building logic don’t have to be messed with.